中国信息通信研究院近日组织完成 2025 年第四季度多模态大模型专项测试工作,最新体系和测试结果如下:
2025年11月至12月测试涵盖多模态理解、文生图与文生视频三项任务,共评估30个模型,其中包括10个多模态理解大模型、10个视频生成模型和10个图像生成模型。
1、多模态理解任务测试结果
多模态理解任务测试旨在考察模型对图像、文本、图表等信息的深层解析与逻辑推理能力,涵盖函数求解、几何分析、表格分析、身份分析、色彩分析、未来预测、关系分析、物理推理、IQ问题维度
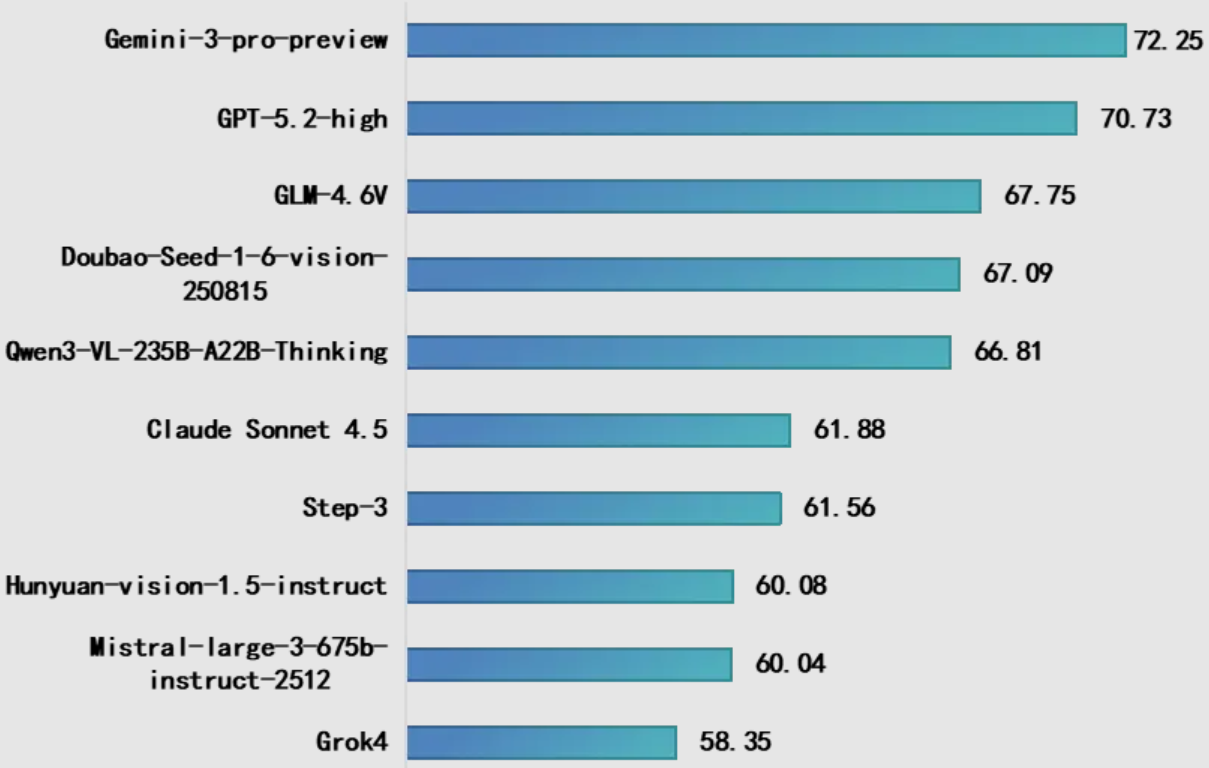
本此测试10个多模态理解大模型,其中国内模型5个,国外模型5个,包括Google Gemini-3-pro-preview、OpenAI GPT-5.2-high、智谱GLM-4.6V、字节跳动Doubao-Seed-1-6-vision-250815等代表性模型。测试结果显示:一是谷歌Gemini-3-pro-preview综合得分位居榜首,其表现小幅领先于 GPT-5.2-High,并显著优于 GLM-4.6V。二是国内模型之间差距较小,GLM-4.6V、Doubao-Seed-1-6-vision与 Qwen3-VL-235B-A22B-Thinking得分高度集中,体现出国内模型在核心能力上的紧追态势。
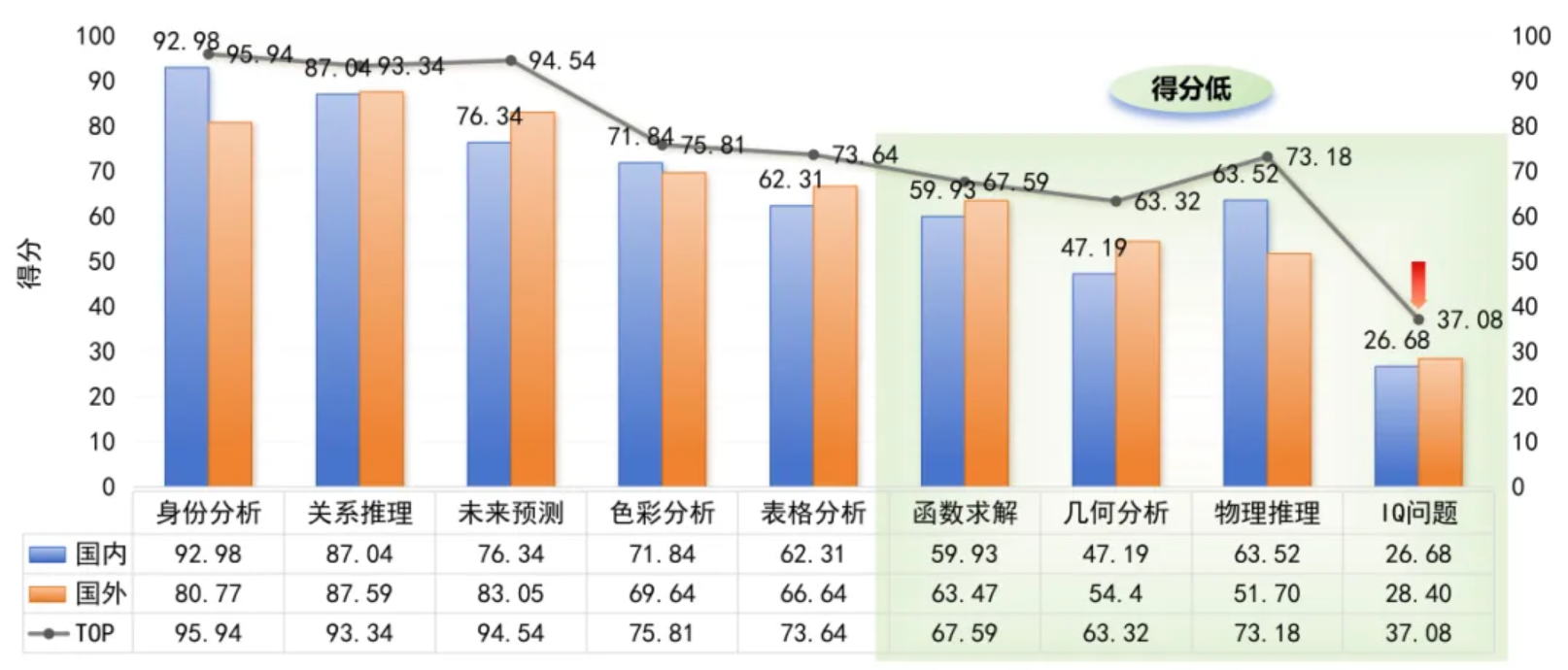
本期测试9类指标,不同维度能力差异明显:从全球模型的整体水平来看,其在身份分析、未来预测、色彩分析等基础任务达到较高能力水平,而函数求解、几何分析和IQ问题等复杂学科、高强度推理任务上仍存在瓶颈。从国内模型的表现来看,其在身份分析、色彩分析、物理推理这类规则明确的任务中表现突出;但未来预测、IQ问题这类涉及开放推理、长程逻辑或场景推演的任务上,仍有较大提升空间。
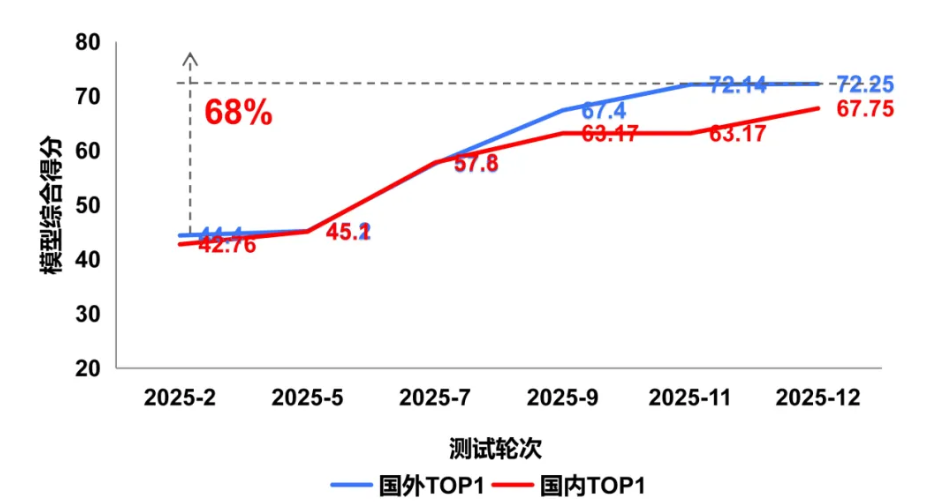
从 2025年2月至12月的持续监测结果看,国内外多模态大模型在图像理解能力均呈现稳步上升态势,反映出多模态理解能力已成为技术竞争的关键赛道。值得关注的是,国内模型视觉理解能力呈现追赶态势,但面向复杂物理世界的理解与推理仍存在一定性能差距。
2、文生图任务测试结果
文生图任务测试考察模型将文本指令转换为高质量图像的能力,核心考察生成图像的色彩表现力、空间构建能力、中国文化表达、主体刻画能力、要素还原能力、色彩表现力、文字创作能力和数量生成能力。
本轮测试10个图像生成模型,其中国内模型6个与国外模型4个,包括字节跳动Seedream 4.5、谷歌Nano Banana Pro、阿里巴巴Wan2.6、Z-Image-Turbo等代表性模型。测试结果显示,一是国外模型暂居领先,谷歌Nano Banana Pro综合得分居榜首,阿里巴巴Z-Image-Turbo以微弱差距紧随其后。二是国内大模型图像生成能力得分接近,字节跳动Seedream 4.5、腾讯HunyuanImage3.0、阿里巴巴Wan2.6能力差距较小,展现出强劲竞争力。

在图像生成能力方面,国内模型在色彩表现、要素还原能力和中国文化表达维度优于国外模型。这一结果表明国内模型在高精度控生成的技术沉淀,也体现出其深耕本土市场数据、适配文化审美偏好的训练路径。然而,当前模型在文字内容生成、数量一致性保持及空间构建等方面仍存在局限,如文字生成易出现细节偏差、数量控制稳定性不足、空间布局与物体关系构建能力亦有欠缺。整体来看,模型对单一元素类指令的执行效果较好,但在“数量-空间位置-物体关联”等复合指令的处理上,仍有较大提升空间。

从2025年2月至12月的连续测试结果看,国内外模型文生图能力水平十分接近,期间整体能力均有明显进步。当前,国内模型在物理空间模拟、复杂要素还原、多轮图像编辑等高阶生成能力方面仍有提升空间。
3、文生视频任务测试结果
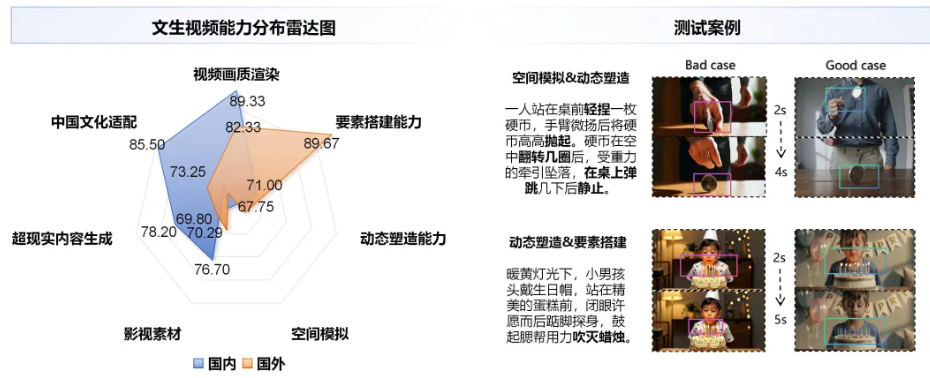
文生视频任务测试考察模型从文本指令生成连贯视频的能力,涵盖视频画质渲染、要素搭建能力、动态塑造能力、空间模拟、影视素材、超现实内容生成和中国文化适配能力。
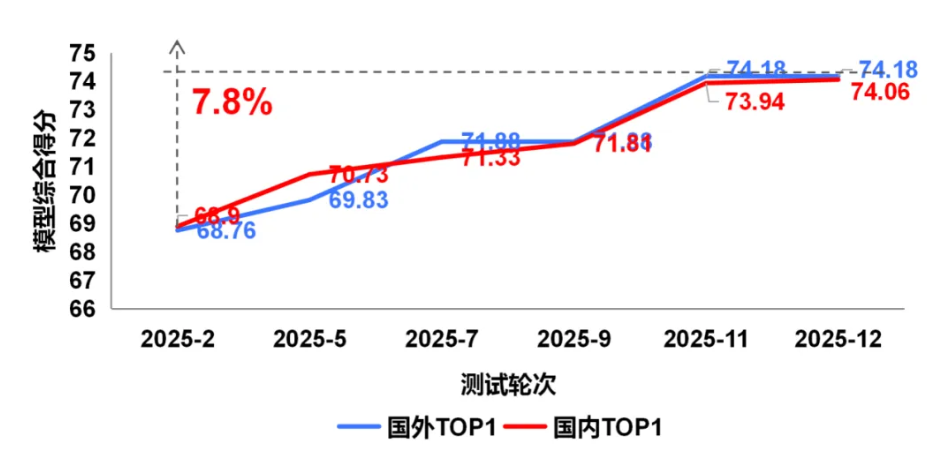
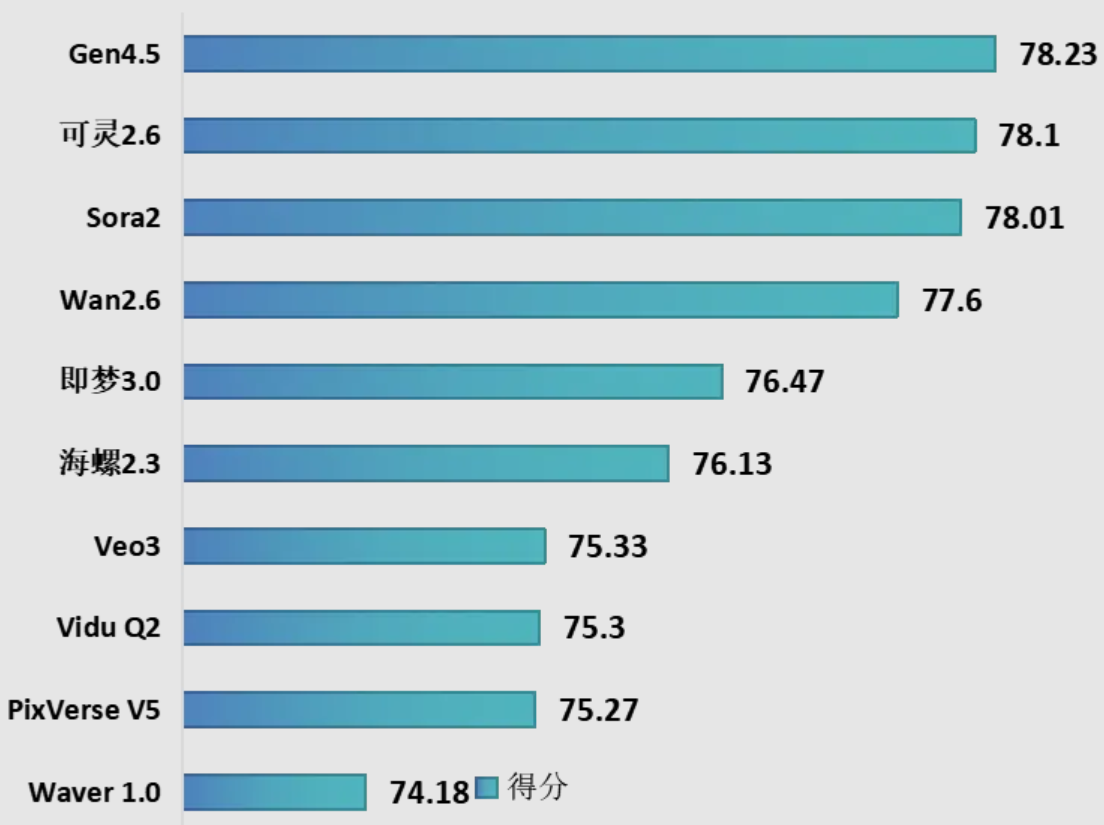
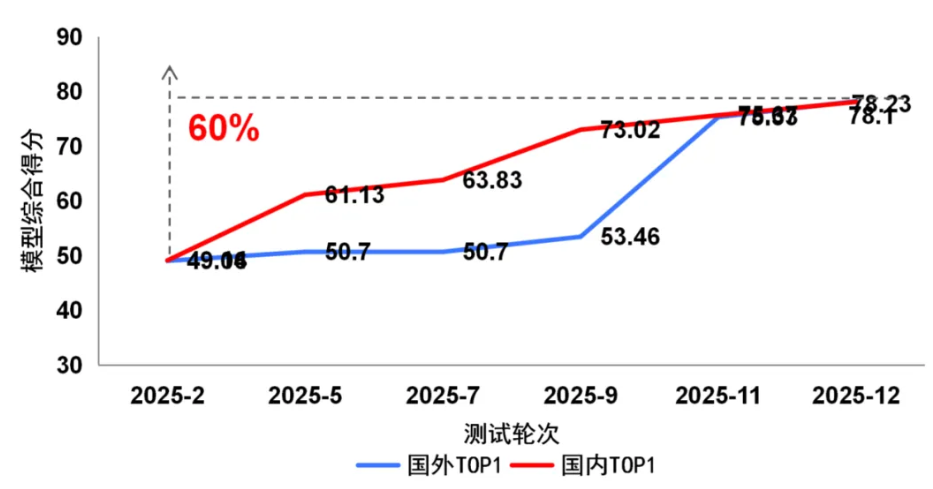
本轮评测10个视频生成模型,其中国内模型7个,国外模型3个,包括Runway Gen-4.5、OpenAI Sora2、快手可灵2.6、阿里巴巴Wan-2.6等主流模型。测试结果显示,一是Runway Gen-4.5在本轮评测中综合排名第一,以微弱优势领先快手可灵2.6。二是国内模型在本次评测前五名中占据三席,分别为快手可灵2.6、阿里巴巴Wan-2.6与字节跳动即梦3.0,在视频生成关键技术指标上达到国际较好水平。三是国内模型的迭代与发布节奏更快,快手可灵从1.0到2.6,在约18个月内进行了超过7次版本迭代,而OpenAI 从Sora到Sora 2的大版本迭代间隔约20个月。
在视频生成能力方面,国内模型在中国文化适配及影视素材生成两个维度的表现显著由于国外模型,体现出其在本土文化内容适配、影视级风格还原上的定向优化成果。国外模型则在空间模拟与要素组织等生成能力上保持一定优势。整体来看,当前模型在动作合理性、过程连贯性以及细节完整性等方面时常出现偏差,尤其在“物理逻辑-动态塑造-场景细节”等复合维度的融合生成能力上,有待进一步加强。
2025年度的持续测试表明,国内头部模型展现出了强劲的迭代能力,在上半年与国际顶尖水平存在差距,至年底已在综合性能上实现并跑。然而,在物理空间模拟、复杂要素搭建等高阶生成能力上,国内外模型仍需持续突破。
“方升-多模态”大模型基准测试体系,构建了覆盖评估指标、数据构建、评测方法、测试工具四大核心层面的全维度评估框架。评估指标设计上,围绕多模态理解与多模态生成两大核心方向,涵盖函数推理、几何分析、图表解析,以及视频流畅性、物理逻辑、图像美学等方面。测试数据集方面,自建累计超20万条多模态数据,视觉理解类数据侧重选择、判断与问答推理能力,文生图、文生视频类数据则聚焦复合提示词的指令遵循效果,为模型的高效评估与优化提供全面支撑。测试方法方面,形成以大模型测试与定量测试相融的多模态协调测试方法,支持多模态交互一致性的高效评估。测试工具方面,紧扣多模态统一评估框架要求,实现对理解、生成及协调能力的一体化自动化评测。